PP-OCR은 바이두에서 개발한 광학 문자 인식 (OCR: Optical Character Recognition) 시스템이다. 2020년에 PP-OCRv1이 나오고 현재 v3까지 업데이트되었다. PP-OCR은 PaddleOCR 이라는 프레임워크로 github에 공개되어있다. 그림 1처럼 OCR과 문서 인식을 위한 다양한 알고리즘을 제공한다. Apache 라이센스라서 원래의 저작자만 명시한다면 이를 가져다 써도 문제는 없다. 하지만 중국에서 개발한 것이라 국내 환경에는 적합하지 않은 테스트 케이스가 많다. 프레임워크화는 잘되어있어서 개인적으로 여기서 제공하는 알고리즘을 실험해보기엔 나쁘지 않은것 같다. 또 논문에서는 경량화된 OCR 시스템을 만들기위해 많은 노력을 쏟았다.

PPOCRv1
PPOCRv1은 2020년도에 발표되었는데 그림 2와 같이 text detection, box rectification, text recognition 세 가지 파트로 구성된다. 경량화를 위해서 비교적 가벼운 backbone을 적용한 것이 특징이다.

text detection은 Differentiable Binarization (DB) 알고리즘을 사용한다. DB는 segmentation 기반의 알고리즘으로 비교적 빠른 Text detection 방법이다. backbone은 MobileNetV3을 쓴다. Text detection을 통해서 box를 검출한 다음에는 box 영역을 Rectification한다. Recognizer에 넣기위한 전처리 단계라고 볼 수 있다. Text recognition 단계에서는 CRNN 모델을 사용해서 feature 추출과 sequence modeling을 한다. loss는 CTC loss를 사용한다. 대략적인 모델은 이렇고 실제로는 SE 모듈, cosine learning rate decay, regularization parameters 변경, PACT quantization 등 성능을 향상시키기 위한 요소 기술이 많이 적용되어있다.
PPOCRv2
PPOCRv2는 v1 모델에서 몇가지 요소 기술이 추가된다. 그림 3의 녹색 박스는 v1과 같고, 빨강 박스가 v2에서 추가된 것들이다. tiny 버전에서는 회색 박스 부분이 적용된다. PPOCRv2는 v1과 같은 inference cost로 정확도가 7% 더 향상되었다고 한다.
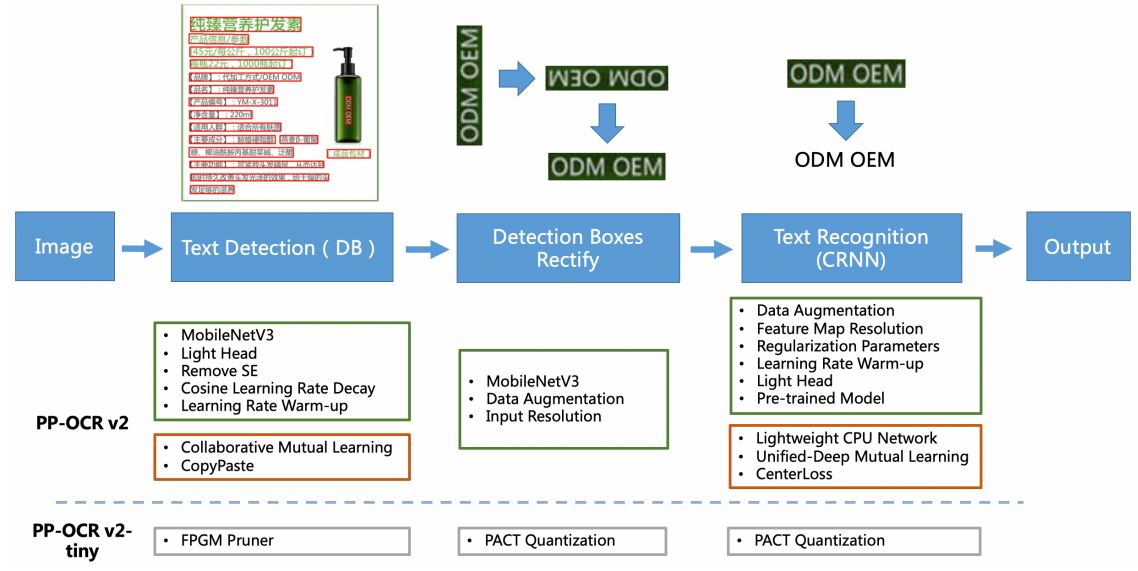
우선 Text detection 시에 Collaborative Mutual Learning(CML)이 추가되었는데 이것은 distillation 방법의 일종이다. 그림 4는 CML 방법을 설명한 것이다.

또 Text Detection 시에 CopyPaste를 통한 data augmentation을 한다. 그림 5는 CopyPaste 방법을 적용한 이미지이다. 녹색 박스가 augmentation 한 것이다.

Text recognition 파트에서도 몇 가지 요소 기술이 추가된다. 우선 Lightweight CPU Network를 적용하고, Unified-Deep Mutual Learning (U-DML)과 Enhanced CTCLoss를 적용한다.
PPOCRv3
2022년에 나온 PPOCRv3에서도 v2 버전을 기반으로 몇 가지 요소 기술이 대체되고 추가된다. PPOCRv3에서는 v2와 비슷한 inference cost를 가지는데 정확도는 5% 더 올랐다고 한다.

Text detection은 v2와 똑같이 CML (Collaborative Mutual Learning) distillation을 사용한다. 추가된 점은 LK-PAN, Deep Mutual Learning, RSE-FPN을 사용하는 부분이다. Text Recognition에서는 더 이상 RNN 계열을 사용하지 않고 Transformer 기반인 SVTR이 적용되었다는 점이 눈에 띈다. 그외에도 Augmentation이나 self-supervised pre-trained model 등 여러가지 요소 기술을 적용했다.
PPOCR이 구현된 Paddle-OCR github에서는 중국어, 영어, 한국어 등 다양한 데이터를 학습한 pre-training 모델을 제공한다. 복잡한 이미지가 아니라면 pre-training 모델을 써도 될정도로 성능은 괜찮은 편이다. 특히 중국어 인식이 아주 잘되는 편이다.
'Computer Vision' 카테고리의 다른 글
| 카메라 캘리브레이션 (Camera Calibration) (0) | 2023.07.04 |
|---|---|
| CNN : Convolutional layer와 Forward 과정의 이해 (0) | 2023.07.04 |
| Text Detection : DPText-DETR (0) | 2023.06.28 |
| CLIP : Contrastive Language-Image Pre-Training 리뷰 (0) | 2023.06.23 |
| Swin Transformer 논문 리뷰 (0) | 2023.06.23 |

