글자 검출 모델 DBNet++ : Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion 논문에 대한 리뷰다. DBNet++는 Segmentation 기반의 글자 검출 방법으로 DB 글자 검출 모델처럼 Differentiable Binarization 방식을 사용하는데, 성능을 더 향상시키기 위해 Adaptive Scale Fusion 모듈이 추가되었다. 그림 1은 MSRA-TD500 데이터셋에 대한 성능을 비교한 것이다. 그림 1에서 볼 수 있듯이 DBNet보다 성능이 더 많이 향상되었다.

Instroduction
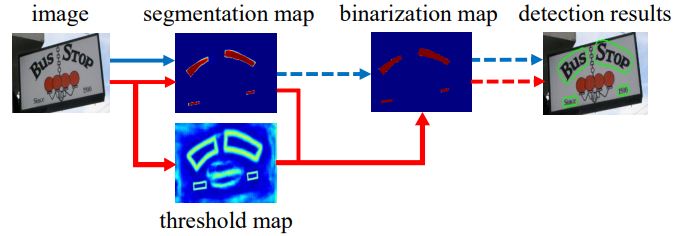
Segmentation 기반 글자 검출 방법은 보통 불규칙한 모양의 글자나 종횡비 차이가 많이 나는 글자를 잡는데 유리하다. 하지만 픽셀을 text instance 영역으로 그룹화하는 복잡한 후처리 작업때문에 추론 시간이 꽤 드는편이다. 그림 2는 본 논문에서 사용하는 후처리 과정이다. DBNet과 같다. 파란 화살표는 고전적인 방법이고 빨간 화살표는 DBNet의 방법이다.
METHODOLOGY
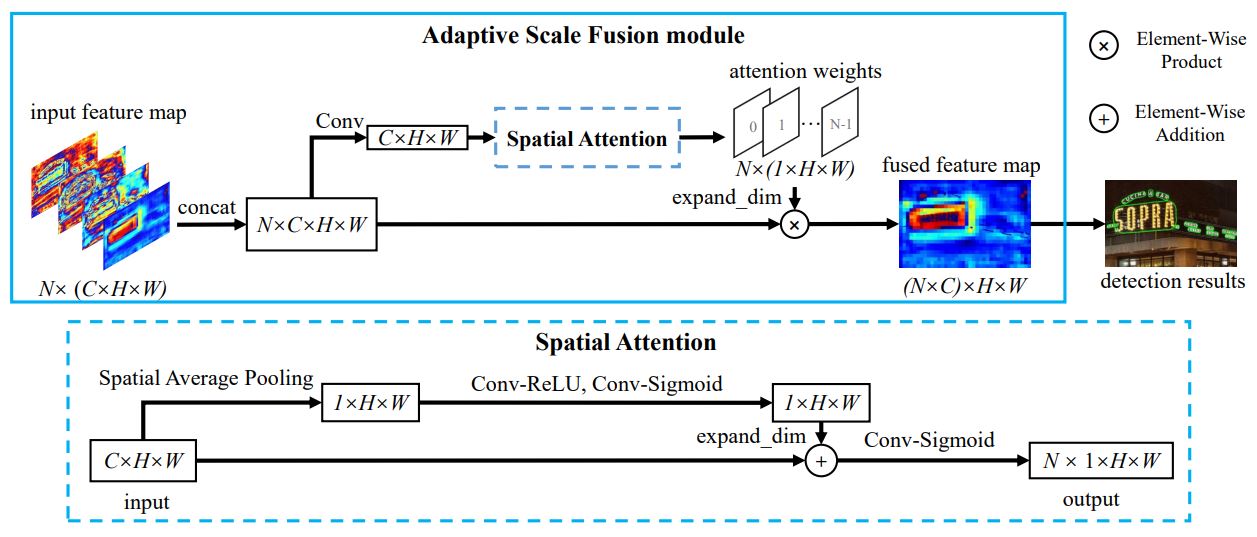
본 논문에서 DBNet과 다른 점은 Adaptive Scale Fusion(ASF) 방법을 사용해서 adaptive하게 multi-scale feature map을 fusion한다. 이렇게 해서 segmentation network의 강건함을 향상시킬 수 있다. ASF는 spatial attention 모듈을 stage-wise attention module로 통합한다. stage-wise attention 모듈은 다른 scale의 feature map weight를 학습하고, spatial attention 모듈은 spatial 차원에 걸쳐 attention을 학습하여 scale에 robust한 feature 융합으로 이어진다.
본 논문에서 제안한 방법의 아키텍처는 그림 3과 같다. 우선 입력이미지를 feature pyramid backbone을 통과시킨다. 다음으로 pyramid feature를 같은 scale로 upsampling하고 Adaptive Scale Fusion 모듈을 적용한다. 이렇게해서 feature F가 나오면 이것을 probability map과 threshold map을 예측하는데 사용한다. 그 다음 probability map과 threshold map을 이용해서 approximate binary map을 구한다. 마지막으로 box 형성 알고리즘을 통해 box 형태로 변환한다.

Adaptive Scale Fusion
다른 scale의 feature는 다른 receptive field를 가지고 다르게 인식한다. 얕고 큰 사이즈의 feature는 작은 text instance의 세부적인 부분을 잘잡지만 큰 text instance의 global한 점을 잘잡지 못한다. 반면 깊고 작은 사이즈의 feature는 반대이다. 그래서 다양한 scale의 feature를 이점을 살리기 위해 feature를 fusion한다. 그림 4는 Adaptive Scale Fusion 모듈이다.
'Computer Vision' 카테고리의 다른 글
| 3D Object Recognition : Point Cloud(Lidar)와 뎁스이미지(Depth-Camera) 데이터에 대한 이해 (0) | 2023.07.15 |
|---|---|
| 딥러닝 Optimizer의 역할과 종류 (0) | 2023.07.13 |
| CNN : 활성화 함수의 종류와 이해 (0) | 2023.07.12 |
| CNN : 다양한 Convolution 연산들 (0) | 2023.07.10 |
| Text Detection : DPTNet 논문 리뷰 (0) | 2023.07.06 |
