Document Image Transformer 라는 이름에서 알 수 있듯이 문서 이미지 관련 Task를 위해 고안된 Self-supervised Pre-training 방법이다. Self-supervised 방식으로 라벨링되지 않은 수 많은 문서 이미지에 대해 pre-training하여 문서의 특징과 패턴을 학습하고, 그 후 Document Layout Analysis과 같은 작업에 backbone 네트워크로 적용할 수 있다. 이 방식으로 문서 이미지 분류, 표 검출, 글자 검출 등에서 성능을 높일 수 있다.
pre-training의 경우 라벨링되지 않은 대량의 데이터에 대한 패턴과 특성을 학습할 수 있다. 따라서 오버피팅을 방지하여 일반화 능력이 더 향상될 수 있고, 랜덤 초기화된 weight로 학습을 시작하는 것보다 학습이 더 빠르게 수렴할 수 있다.
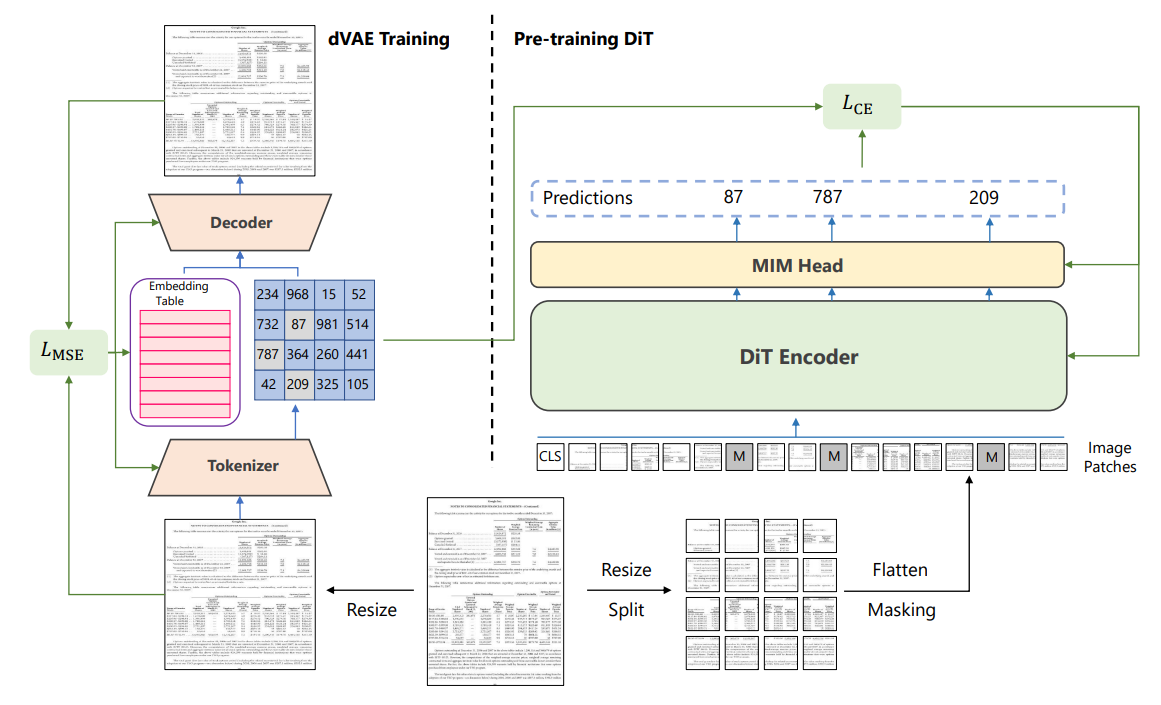
해당 논문에서는 vanillar Transformer 아키텍처를 사용했다. 일반적인 Vision Transformer와 같이 입력 이미지를 패치 단위로 분할하고 임베딩한다. 그리고 multi-head attention으로 구성된 transformer encoder block에 입력한다.
Pre-training 전략
(1) Masked Image Modeling
이미지의 일부분을 마스킹하고, 마스킹된 부분을 예측하는 방식으로 모델을 학습시킨다. 여기서 이미지를 이미지 패치와 visual token으로 표시한다. pre-training 중에 DiT는 이미지 패치를 입력으로 받아들이고 출력 표현으로 visual token을 예측한다. 자연어처리에서 쓰는 text token과 마찬가지로 이미지는 image tokenizer에서 얻은 일련의 개별 token으로 표현될 수 있다.
* OpenAI에서 개발한 DALL-E의 dVAE(Discrete Variational Auto-Encoder)를 이미지 tokenizer로 사용하는데, 이것은 4억 개의 이미지를 포함한 대규모 데이터 컬렉션에 대해 학습되었지만, 자연 이미지에서 학습된 것은 문서 이미지와 도메인이 다르므로 4,200만 개의 문서 이미지가 포함된 IIT-CDIP 데이터 세트에서 dVAE를 학습한다.
모델을 효과적으로 pre-training하기 위해 일련의 이미지 패치가 제공된 특수 token [MASK]을 사용하여 입력데이터를 무작위로 마스킹한다. Encoder는 Positional Embedding이 추가된 Linear Projection을 통해 마스크된 패치 sequence를 임베딩하고 이것을 Transformer block stack으로 보낸다. 모델은 마스킹된 위치의 출력을 사용하여 visual token의 index를 예측해야한다.
Transformer 부분의 구현 세부 사항으로 base 모델과 large 모델이 있는데,
base 모델은 768 hidden size와 12 attention head를 가진 12개의 Transformer layer 사용하고 feed-forward 네트워크 사이즈는 3072이다.
large 버전 모델은 1024 hidden size와 16 attention head를 가진 24개의 Transformer layer 사용하고 feed-forward 네트워크 사이즈는 4096이다.
이것을 backbone으로 사용하고 Detection task에 적용하기 위해서는 Mask R-CNN, Cascade R-CNN 등의 방식을 뒤에 적용하면 된다.
'Computer Vision' 카테고리의 다른 글
| VIPTR 글자 인식 모델 (0) | 2025.04.17 |
|---|---|
| A Hybrid Approach for Document Layout Analysis in Document images 논문 리딩 (0) | 2024.07.05 |
| Self-Supervised Learning (0) | 2024.06.14 |
| 수식 인식 BTTR 모델 (0) | 2024.01.09 |
| Weight 초기화 방법들 (0) | 2023.09.19 |


