paper : https://arxiv.org/pdf/2401.10110.pdf
2024년도에 CVPR에 accept된 글자 인식 논문으로, CNN과 여러 self-attention 메커니즘들의 중요한 특성을 활용하여, 계층적 vision transformer에서 영감을 받은 아키텍처를 통해 글자 인식을 위한 고성능 네트워크의 패러다임을 제안한 논문.
현재 가장 높은 성능을 보이고 있는 모델들은 주로 visual encoder와 sequence decoder를 결합한 하이브리드 아키텍처에 의존하고 있지만, 이러한 구조는 추론 효율성이 낮다는 단점이 있다. 이 논문에서는 전통적인 sequence 디코더를 사용하지 않고, 대신 여러 self-attention 계층을 특징으로 하는 피라미드 구조의 visual-semantic 추출기를 사용한다. 실제로 해당 논문에서는 다양한 데이터셋에서 우수한 성능이 나오는 것을 검증했다고 한다.
이 논문의 Main Contribution은 다음과 같다.
- self-attention 메커니즘에 기반한 single visual 모델로 높은 성능을 달성했는데 self-attention 메커니즘의 계산을 가속화하기 위해 sparse operator와 다양한 attention 조합을 사용해서 성능과 속도의 균형을 달성함.
- text 인식을 위한 맞춤화된 feature 추출 모듈인 VIPTR을 제안함. 이 모듈은 어떤 길이의 텍스트 이미지 입력에도 적응하고 인식할 수 있으며, 다양한 언어에 대한 인식 범용성을 가지고 있다고함.
모델의 세부적인 특징
패치 기반 분할 - VIPTR은 다른 일반적인 Vision Transformer와 같이 텍스트 이미지를 여러 2D 패치로 균등하게 나누고, 각 패치는 문자의 일부 또는 배경을 포함한다. 이렇게 패치를 나누면 문자의 지역적 특징을 동시에 추출하고 다른 문자 간의 잠재적 문맥 의미적 의존성을 포착하는 데 도움이 된다.
조건부 위치 임베딩 (CPE) - 각 token mixing attention 모듈에서 VIPTR은 조건부 positional embedding을 사용하여 문자의 지역 정보를 탐색한다. 이것은 문자 간의 상대적 위치 정보를 더 잘 모델링하는 데 도움이 됨.
맨해튼 self-attention (MaSA) 및 CSWin attention - 이 메커니즘은 문자의 지역 정보 탐색에 사용되며, 문자 간의 지역적 관계와 문맥을 효과적으로 모델링함.
중첩 공간 축소 attention (OSRA) - 글로벌 의존성을 모델링하기 위해 사용되며, 수평 방향과 수직 방향에서 문자 간의 글로벌 관계를 모델링함. 이는 텍스트 이미지의 긴 텍스트 인식 효과를 개선하는 데 도움이 됨.
피라미드 구조 - VIPTR은 다단계 local 및 global 정보의 하이브리드 모델링을 위한 피라미드 구조를 사용함. 이는 텍스트 이미지의 특징 추출 능력을 향상시킴.
시간 복잡도와 입력 이미지 길이의 제약 개선 - VIPTR은 SWin과 비교하여 시간 복잡도를 줄이고, 고정 크기의 마스크 그룹을 사용하여 입력 이미지 길이를 제한할 필요가 없음.
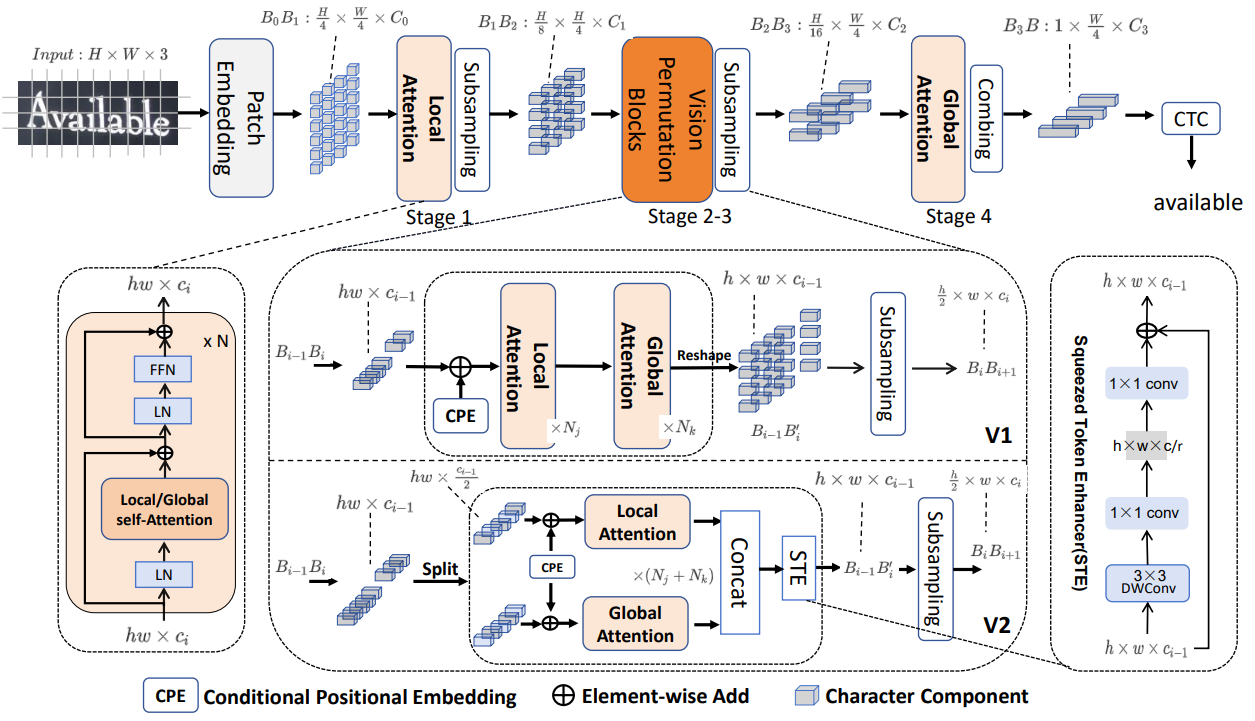
VIPTR의 아키텍처는 height가 3-step으로 점진적으로 감소하는 4 Stage 네트워크로 구성된다. 주어진 H × W × 3 크기의 이미지 텍스트는 두 계층의 CNN 기반 패치 임베딩을 통해 패치로 초기 변환된다. 이후 다양한 scale에서 네 단계의 특징 추출이 수행되며, 각 단계는 self-attention 기반 하이브리드 블록의 시리즈로 구성되고, height 차원을 따라 downsampling 또는 global average pooling 연산을 사용한다. local 및 global attention 블록 모두 문자 특징 추출에 집중하고 문자 구성 요소 간의 의존성을 포착하는 데 사용된다. 이 추출기는 다양한 거리와 다중 스케일에서 문자 구성 요소 특징을 포착하고, 문자 구성 요소 간의 문맥 의존성을 특징짓는데 사용된다. 마지막으로, CTC 디코더는 문자 sequence에 대해 선형 예측과 중복 제거를 수행하여 인식 결과를 얻는 데 사용된다. 이 접근 방식은 문자 구성 요소의 특징과 그들 사이의 의존성을 효과적으로 포착하여 정확한 텍스트 인식을 가능하게 한다.

학습시 사용한 하이퍼파라미터는 위 그림과 같이 설정했다. 눈 여겨 볼만한 점은 영어는 이미지 사이즈를 작게하고, 중국어는 이미지 사이즈를 320으로 비교적 크게 설정했다는 점.
한국인이 작성한 논문이 아니라 한국어에 대한 성능은 없지만, 영어에서도 높은 성능을 달성하고 특히 중국어에 아주 높은 성능을 내고 있다.
'Computer Vision' 카테고리의 다른 글
| Vision RAG (VISRAG: Vision-Based Retrieval-Augmented Generation On Multi-Modality Documents) (0) | 2025.04.17 |
|---|---|
| Llama 3.2 멀티모달 모델 리서치 (0) | 2025.04.17 |
| A Hybrid Approach for Document Layout Analysis in Document images 논문 리딩 (0) | 2024.07.05 |
| DiT (Self-supervised Pre-training for Document Image Transformer) (1) | 2024.07.05 |
| Self-Supervised Learning (0) | 2024.06.14 |



