메타에서 이미지 분석 기능이 포함된 첫 멀티모달 모델인 Llama 3.2 가 공개되었다. 이미지 분석 기능이 포함된 모델은 11B와 90B 모델이다. 그 외에도 텍스트만 처리하는 경량화 모델인 1B, 3B 모델을 같이 공개했다.
메타에서 Llama 3.2 모델 개발을 위해 적용한 요소 기술과 학습 방법은 다음과 같다.
Multi-Modal 모델
모델 아키텍처의 변화
멀티모달 모델인 11B와 90B 모델은 이미지 처리 작업을 처리하기 위해 기존 LLM과 다른 모델 아키텍처를 사용한다. 구체적으로 이미지 입력을 지원하기 위해 pre-training된 이미지 Encoder를 추가로 사용하고, 이것을 pre-training된 언어 모델에 통합하는 Adapter Weights 세트를 학습했다고 한다. 이미지를 입력받을 수 있도록 하기 위해 어댑터(adapters)가 추가된 셈인데, 이 어댑터는 크로스 어텐션(cross-attention) 레이어로 구성되어 있으며, 이미지 인코더(image encoder)가 생성한 이미지 표현을 텍스트 모델에 통합한다. 이미지 표현을 언어 표현과 일치시키기 위해 text-image 쌍에 대해 Adapter를 학습한다.
학습 파이프라인
Llama 3.2는 데이터 양을 조절하여 세 단계에 걸쳐 학습하였다. 먼저 Adapter 학습이다. 이미지 Encoder와 Adapter를 추가한 다음 대규모 데이터(이미지, 텍스트) 쌍 데이터를 pre-training한다. Adapter 학습중에는 이미지 Encoder의 파라미터는 업데이트했지만, Text 전용 기능은 그대로 유지하기 위해 언어 모델의 파라미터는 업데이트하지 않는다. 다음으로 중간 규모의 고품질 인-도메인(in-domain) 데이터와 지식이 강화된 텍스트-이미지 쌍 데이터를 사용해 추가 학습을 한다. 마지막 post-training으로 텍스트 모델의 후처리와 유사하게 supervised learning 기반의 정렬, rejection sampling, DPO 등을 통해 모델을 학습한다. 합성 데이터를 사용해 질문-답변 데이터를 생성하고, 기존에 개발된 Llama 3.1 모델로 이를 필터링하고 보강한다. 또한, 보상 모델을 사용하여 생성된 답변의 순위를 매기고, 고품질의 데이터로 모델을 fine-tuning한다. 이 과정에서 안전성 데이터도 추가해, 안전하면서도 유용한 모델을 제공한다고 한다.
경량화 모델
메타에서 1B와 3B 모델도 같이 공개했다. 이 경량화 모델은 Pruning과 Distillation 기술을 적용했다고 한다.
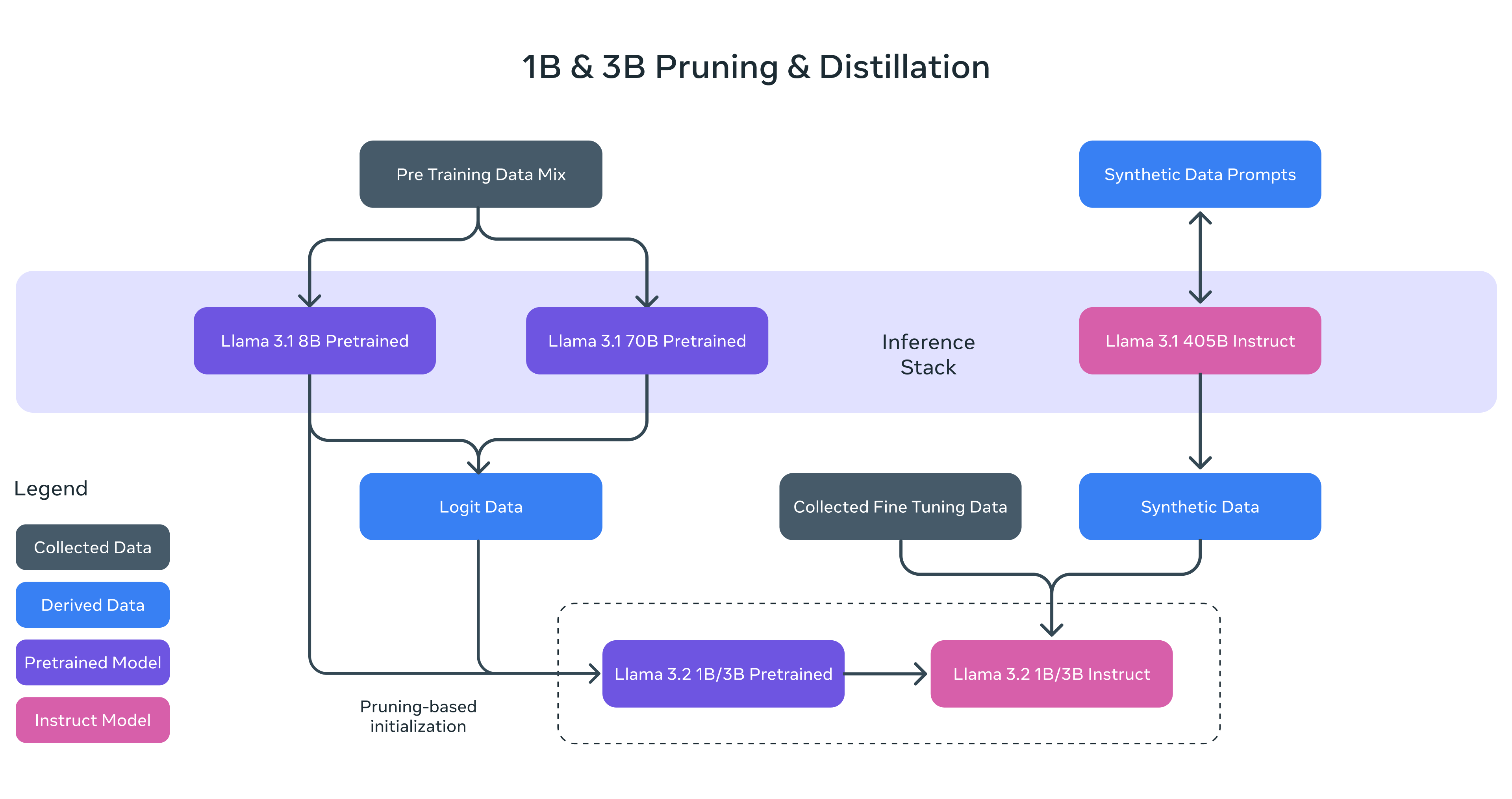
Pruning
Pruning은 만들어진 모델의 크기를 줄이는 방식이다. 모델에서 불필요하거나 덜 중요한 부분을 제거하여 더 작은 모델로 만드는 방법으로, Llama 3.1의 8B 모델을 기반으로, 1B와 3B 모델에 대해 구조적 structured pruning을 적용했다고 한다.
이 과정은 네트워크의 일부를 체계적으로 제거하는 것과 관련이 있으며, 이를 통해 모델의 가중치와 gradient의 크기를 조정하여 성능을 유지하면서 더 작은 모델로 만들었다.
knowledge distillation
knowledge distillation은 더 큰 네트워크가 작은 네트워크에 지식을 전달하는 방식이다. 이 방식의 장점은 작은 모델이 처음부터 학습하는 것보다 더 나은 성능을 거둘 수 있다는 것이다.
1B와 3B Llama 3.2 모델을 훈련할 때, Llama 3.1의 8B와 70B 모델에서 나온 logits을 사용했다고 한다.(logit은 처리하지 않은 순수 모델 출력이다)
logit은 모델이 예측한 확률 분포(또는 출력)를 의미한다. 더 큰 모델이 출력한 로짓을 작은 모델의 token 수준 목표(token-level targets)로 사용하여 작은 모델이 더 효과적으로 학습할 수 있도록 한다.
knowledge distillation은 pruning 이후에도 사용되었는데, pruning을 통해 모델을 압축한 후 손실된 성능을 회복하기 위해 지식 증류를 통해 더 큰 모델로부터 작은 모델로 지식을 전달한 것이다.
Post-Training 과정
Llama 3.1에서 사용된 방식과 유사하게, post-training에서는 여러 번의 alignment 과정을 거쳐 최종 모델을 만든다. alignment는 모델의 성능을 더 세밀하게 조정하기 위한 단계로, supervised learning 기반의 Fine-tuning , RS(Rejection Sampling), 그리고 DPO(Direct Preference Optimization) 세 가지 방법이 사용된다.
SFT (Supervised Fine-Tuning) : 사람이 레이블을 지정한 데이터로 모델을 더 미세하게 조정하는 과정이다. 이를 통해 모델이 더 정확한 답변을 생성할 수 있도록 한다.
RS (Rejection Sampling) : 모델이 생성한 여러 개의 답변 중에서 가장 적합한 답변을 선택하여 학습하는 방법이다. 이 과정에서 품질이 낮은 답변은 거부되고, 높은 품질의 답변만을 채택하여 모델을 개선한다.
DPO (Direct Preference Optimization) : 사람의 선호도를 바탕으로 모델이 생성하는 답변의 질을 향상시키는 방법이다. 모델이 더 나은 답변을 할 수 있도록 직접적으로 선호 데이터를 반영하여 최적화한다.
context length 지원 확장
context length란 모델이 한 번에 처리할 수 있는 입력 토큰의 수를 의미하는데, Llama 모델은 128K 토큰까지의 문맥을 처리할 수 있도록 확장되었으며, 이 과정에서도 기존 사전 학습된 모델의 품질을 유지할 수 있도록 했다고 한다. 이를 통해 모델은 긴 문서를 요약하거나 여러 정보 출처를 한꺼번에 처리하는 등 더 복잡한 작업을 수행할 수 있다.
'Computer Vision' 카테고리의 다른 글
| Multi-Modal 핵심 개념 (0) | 2025.04.29 |
|---|---|
| Vision RAG (VISRAG: Vision-Based Retrieval-Augmented Generation On Multi-Modality Documents) (0) | 2025.04.17 |
| VIPTR 글자 인식 모델 (0) | 2025.04.17 |
| A Hybrid Approach for Document Layout Analysis in Document images 논문 리딩 (0) | 2024.07.05 |
| DiT (Self-supervised Pre-training for Document Image Transformer) (1) | 2024.07.05 |


