Semantic Segmentation이란?
Semantic Segmentation은 컴퓨터 비전 분야에서 중요한 작업 중 하나로, 디지털 이미지 또는 비디오를 픽셀 수준에서 분석하여 이미지 내의 개별 객체 또는 영역을 식별하는 기술이다. 이미지의 각 픽셀에 대해 클래스 레이블을 할당하는 작업이라고 할 수 있다. 이를 통해 이미지의 각 부분을 특정 객체 또는 영역으로 식별할 수 있다. 예를들면 아래 사진과 같이 이미지의 픽셀들을 분류해서 해당 픽셀이 자동차인지 도로인지 하늘인지 어떤 클래스에 속하는지 파악하는 Task이다.

Semantic segmentation은 픽셀마다 정확한 레이블을 할당하기 때문에 픽셀 수준에서 객체의 경계를 정확하게 추출할 수 있다. 이를 통해 객체의 크기, 모양, 위치 등을 추론할 수 있으며, 다른 컴퓨터 비전 작업에 유용한 정보를 제공할 수 있다. 자율 주행차, 의료 영상 분석, 로봇 공학, 보안 시스템 등 다양한 응용 분야에서 활용할 수 있다.
문제점
Semantic segmentation은 주로 픽셀 기반으로 작업하기 때문에 고해상도 이미지에 대한 연산 부하가 크다. 또한 이미지가 선명하지 않거나 경계가 명확하지 않은 경우 정확히 영역을 분할하지 못하는 경우도 많이 발생한다. 아래 사진은 2016년에 공개된 SegNet[1] 결과 사진이다. 나름 잘 분할을 했지만 아주 매끄럽지는 않아서 성능이 좋다고 보기는 힘들다. 비교적 오래된 모델이지만 최신 기술들도 아직 완벽하게 동작하지는 않는다.

Semantic Segmentation 기술
Semantic Segmentation은 주로 딥러닝 기술을 기반으로 한다. 주로, 컨볼루션 신경망(Convolutional Neural Network, CNN)이 이미지의 로컬한 패턴을 학습하여 픽셀마다 클래스를 예측하는 데 사용된다. U-Net, SegNet, DeepLab, PSPNet 등과 같은 CNN 기반의 아키텍처와 최근에는 Transformer를 이용한 방법도 연구되고 있다.
Segmantic Segmentation 관련 주요 공개 데이터셋은 다음과 같다.
PASCAL VOC : 이미지의 해상도는 다양하며 사람, 자동차, 개, 고양이, 새, 의자, 자전거, 식탁 등의 20개의 클래스로 구성되어 있다. 주로 자연 환경에서 촬영된 이미지이다.
MS COCO : 이미지의 해상도는 다양하며, 다양한 배경과 환경에서 촬영된 실제 이미지로 사람, 자동차, 개, 고양이, 새, 의자, 자전거, 식탁 등 총 80개의 객체 클래스로 구성되어 있다.
Cityscapes : 도시 거리 이미지로 구성되어 있다. 이미지는 고해상도이고, 주로 독일의 도시들에서 촬영되었다고한다.
ADE20K : 실내 및 실외 환경에서 촬영된 고해상도 이미지로 구성되고 거실, 부엌, 사무실, 도서관, 거리, 공원 등 다양한 환경을 포함하고 있다.
이러한 데이터셋은 다양한 클래스 레이블과 픽셀 수준의 annotation을 포함하고 있어 모델 학습에 사용된다.
성능 평가 Metrics
Semantic segmentation의 성능은 몇 가지 metrics로 평가될 수 있다[2]. 평가 metrics로는 IoU(Intersection over Union) 또는 mIoU(mean Intersection over Union), PA(Pixel Accuracy), MPA(Mean Pixel Accuracy), Dice coefficient가 있다.
IoU : IoU는 예측된 영역과 실제 영역의 겹치는 부분의 비율을 측정하는 것이다.

mIoU : mIoU는 모든 클래스에 대한 IoU의 평균값이다.
PA : 화소 정확률로 분모는 전체 화소수, 분자는 맞힌 화소 수이다.

MPA : class 별로 PA를 구하고 평균한 값이다.

Dice : ground truth와 prediction의 겹쳐지는 영역에 2를 곱하고, 두 이미지의 총 픽셀 수로 나눈 값이다. Medical image analysis에서 많이 사용하는 metric이다.

FCN (Fully Convolutional Network)
FCN[3]은 Semantic Segmentation을 처음 시도한 Convolution 신경망이다. 초기 CNN은 앞부분은 Convolutional layer, 뒷부분은 Fully Connected layer로 구성되어 주로 classification 문제를 풀었는데, FCN에서는 Fully Connected layer를 제거하고 Convolution과 Pooling layer만으로 구성했다.
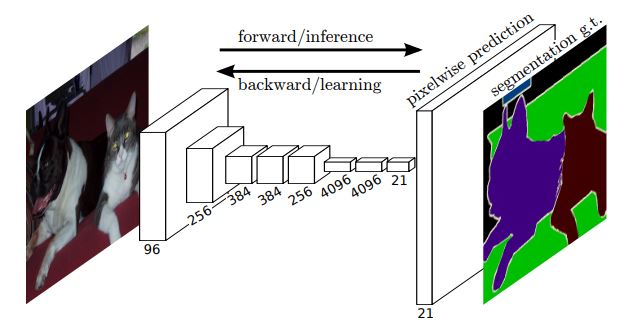
FCN의 특징으로 픽셀 분할을 위해 feature map을 줄이기만 하지않고 upsampling하여 feature map의 공간적인 해상도를 복원한다. upsampling은 픽셀 간의 공간적인 간격을 확장하여 고해상도 feature map을 생성하는 과정이다. FCN에서는 전치 컨볼루션(transposed convolution)을 사용해서 upsampling을 한다. 전치 컨볼루션은 map의 크기를 복원하지만 값은 복원하지 않는데, 전치 컨볼루션을 위한 필터는 학습으로 알아낸다. FCN에서 입력은 h x w 컬러 영상이고 출력은 입력 영상과 같은 크기의 h x w 맵에 클래스 개수를 나타내는 텐서가 추가된다. 즉, h x w x (C+1) 텐서다. C는 클래스 개수를 나타낸다. 출력층에서는 각 픽셀의 위치에 softmax를 적용해서 한 픽셀은 C+1개의 클래스 확률을 표현한다. 이는 원 핫 인코딩으로 표현된다.
FCN 이후에 FCN을 변형하여 성능을 더욱 향상시킨 DeConvNet, U-net, DeepLab 과 같은 다양한 Semantic Segmentation 방법들이 나왔다.
U-net
U-net[4]은 의료 영상을 분할할 목적으로 개발되었다. 아래 그림은 U-net의 구조이다. 다른 컨볼루션 신경망과 마찬가지로 Convolutional layer와 max pooling을 통해서 feature map의 공간 해상도는 줄이고 깊이는 늘어난다. 이 과정을 4번 반복하면 32x32x512 feature map이 된다. 여기서부터는 전치 컨볼루션을 이용해서 upsampling한다. U-net은 원래 의료 영상을 분할할 목적으로 만들어져서 입력 영상이 572x572x1로 gray 영상이다. 최종 출력은 388x388x2 map으로 물체와 배경 두가지를 분할할 수 있다. 실제로는 이것을 응용해서 채널이 3개인 color 영상을 받고 출력 맵이 여러 채널을 가지도록해서 여러 class를 분할하게 수정해서 사용할 수 있다.

Semantic Segmentation 같은 경우에는 모든 픽셀에 class를 할당하여 영역을 분할하지만 같은 객체 타입인데 다른 instance인 경우에도 모두 같은 부류로 구분한다. 같은 부류의 객체가 여럿인 경우 이를 따로 구하고 싶으면 Instance Segmentation 방식을 적용하면 된다.
'Computer Vision' 카테고리의 다른 글
| Deformable Convolutional Networks (DCN) 리뷰 (0) | 2023.06.13 |
|---|---|
| Text Detection : Real-time Scene Text Detection with Differentiable Binarization 논문 리뷰 (0) | 2023.06.09 |
| MatCha - 차트 vision-language 추론 모델 (0) | 2023.05.30 |
| Image Detection Transformer (DETR) (0) | 2023.05.26 |
| Vision Transformer (0) | 2023.05.23 |



