최근에 이미지 인식의 다양한 분야에 Transformer[1]가 적용되어 높은 성능을 달성하고 있다. 예전에는 Convolutional Layer를 겹겹이 쌓는 방식으로 이미지의 특징을 추출하고 이를 통해 이미지를 인식하는 방법이 대세였지만 Vision Transformer[2] 이후 이미지 인식 패러다임이 많이 바뀌고 있다는 것이 느껴진다.
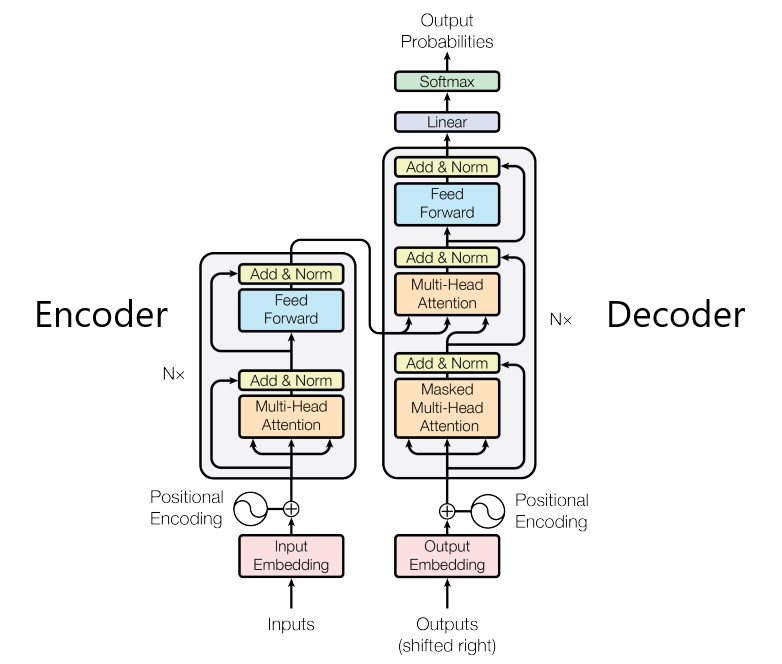
Transformer는 주로 자연어 처리 분야에 적용되어 높은 성능을 이끌어왔다. 최근 몇 년간 자연어 처리의 많은 Task에서 SOTA를 이룬 BERT, GPT 언어모델은 각각 Transformer의 Encoder와 Decoder를 기반한 모델이다. Transformer의 특징은 RNN, CNN과는 다르게 Attention만을 활용해 모델을 구축한 것이다. 그림 1과 같이 Encoder-Decoder 구조로 이루어졌으며, Attention이 적용되어 데이터 간의 관계를 파악한다.
자연어 처리 분야는 Transformer를 기반한 이러한 BERT와 GPT와 같은 언어모델을 pre-training한 후 downstream task에 따라 fine-tuning하는 방식으로 일반화 되었다고 할 수 있다.
그러면 이미지 인식 분야에서는 Transformer가 어떻게 적용이 될까?
자연어처리 분야에 적용되어 높은 성능을 내던 Transformer는 이미지 인식 분야에서는 제한된 범위에서 일부 요소 기술로 적용되어오다가 점점 CNN의 성능을 능가했다. 이전에는 이미지의 특성상 Transformer보다는 Convolution이 특징을 추출하기 유리했다. 하지만 Vision Transformer가 적용되어 CNN과 비견될 정도로 높은 성능을 달성했다는 연구결과가 나왔고, 이는 이미지 인식 분야에서도 Transformer가 충분히 유용하다는 것이 입증되었다. Classification 뿐만 아니라 Detection(DETR[3]), Segmentation(SETR[4]), Tracking(MOTR[5]) 등의 분야에서도 Transformer가 적용되어 높은 성능을 보이고 있다.
그렇다면 이미지에 Transformer가 어떻게 적용되는지 알아보자. 그림 2는 Vision Transformer 구조[2]이다.

Vision Transformer는 이미지를 고정된 크기(16x16)의 패치로 분할하고 이 패치들을 input으로 사용하게 된다. 일반적인 Transformer는 1D sequence 데이터를 입력으로 받는다. 따라서 16x16으로 분할된 패치들은 1-Dimension으로 변환한다. 2D 이미지를 처리하기 위해 이미지 x ∈ RH×W×C를 Flatten 2D 패치 xp ∈ RN×(P 2 ·C) sequence로 재구성하고, 여기서 (H, W)는 원본 이미지의 해상도이고 C는 채널 수, (P, P)는 이미지 패치의 해상도이고 N = HW/P2는 결과 패치 수이며, 이는 Transformer의 입력 시퀀스 길이로도 사용된다. Transformer는 일정한 latent 벡터 크기를 사용하므로 패치를 평면화하고 학습 가능한 Linear Projection을 사용하여 D차원에 매핑한다. 이 Projection의 출력을 패치 임베딩이라고 한다. 그리고 Classification 작업에 사용될 Classification Token 벡터가 추가되어진다. 각각의 패치에 대해서는 이미지에서 차지하는 위치 정보가 패치별로 포함되어 임베딩된다. 이렇게 임베딩된 Vector Sequence를 Transformer Encoder에 넣는다.
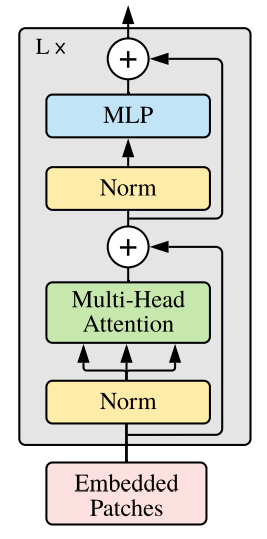
Vision Transformer에서 사용하는 Transformer Encoder는 기존 Transformer Encoder와는 차이점이 있다. Transformer 같은 경우 일반적으로 Layer를 깊게 쌓을수록 학습이 힘들기 때문에 Normalization 과정이 필요하다. 일반 Transformer에서는 Multi-Head Attention을 수행한후 Normalization을 하지만 Vision Transforemr에서는 Layer Normalization을 수행하고 Multi-Head Attention을 적용한다. Self-Attention 수행시 768차원이던 데이터가 64차원으로 줄어들기 때문에 Self-Attention을 12번 수행하여 768차원으로 출력을 내보낸다. Transformer Encoder에서 Multi-Head Attention을 거치고 나온 출력은 Classification을 위한 MLP 모델에 넣고 최종적으로 Class를 예측하게 된다.
Vision Transformer는 위 과정을 거쳐서 이미지 Classification을 수행하게 된다. CNN과 Transformer를 비교하자면 CNN의 경우 지역적인 정보를 중요하게 생각하고 Transformer는 지역적인 정보를 상대적으로 덜 중요하게 여기면서 모델의 자유도를 높인다. Vision Transformer는 CNN과 달리 inductive bias가 적은 관계로 좋은 성능을 내기 위해서는 굉장히 많은 데이터가 필요하거나 Augmentation과 Regularization을 신경써야한다. 충분한 양의 데이터가 있다면 기존의 CNN 모델을 뛰어넘는 성능을 낼 수 있지만 적은 수의 데이터에서는 Transformer가 오히려 성능이 떨어질 수 있다는게 단점이다. 따라서 학습 데이터가 충분할 때 사용하는 것이 좋다. 최근에는 Transformer를 보완하기 위한 연구가 활발히 진행되고 있고 적은 데이터 수로도 높은 성능을 내는 Data Efficient Transformer 기술 등이 연구가 되고있다.
Reference
[1]. Attention Is All You Need : https://arxiv.org/abs/1706.03762
[2] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE : https://arxiv.org/abs/2010.11929
[3] End-to-End Object Detection with Transformers : https://arxiv.org/pdf/2005.12872.pdf
[4] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers : https://arxiv.org/abs/2012.15840
[5] MOTR: End-to-End Multiple-Object Tracking with TRansformer : https://arxiv.org/pdf/2105.03247v1.pdf
'Computer Vision' 카테고리의 다른 글
| Semantic Segmentation 개요:개체 영역 식별에 대한 소개 및 주요 문제 (0) | 2023.06.08 |
|---|---|
| MatCha - 차트 vision-language 추론 모델 (0) | 2023.05.30 |
| Image Detection Transformer (DETR) (0) | 2023.05.26 |
| Text Detection : Arbitrary Shape Text Detection via Boundary Transformer (TextBPN++) 논문 리뷰 (0) | 2023.05.23 |
| 딥러닝 모델 경량화 방법 (0) | 2023.05.15 |


